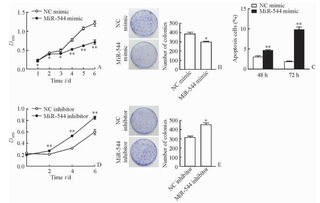
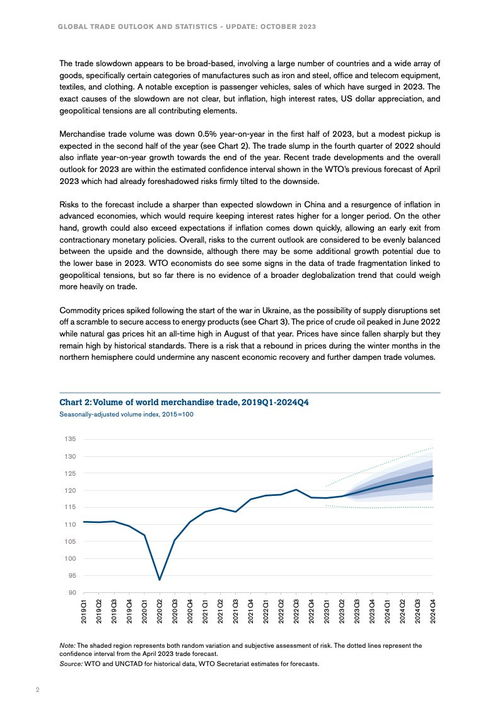
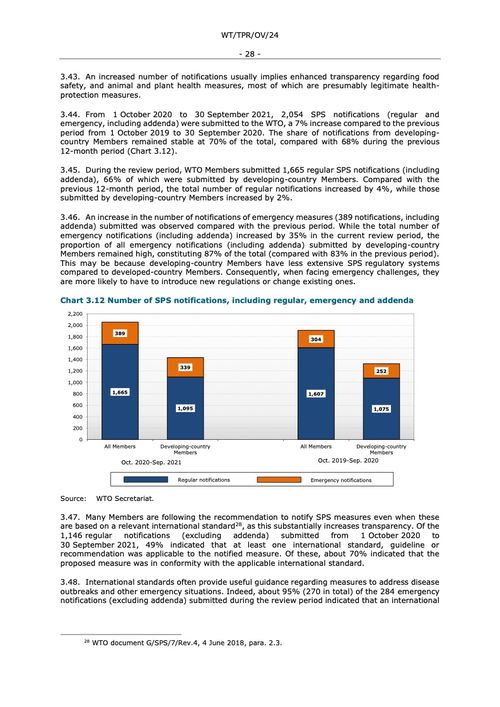
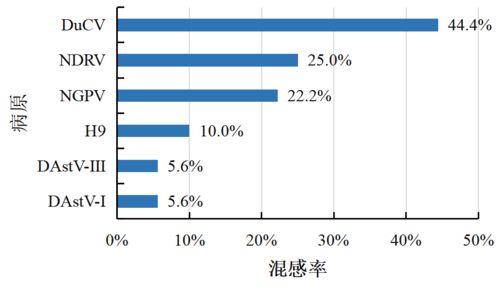
2023年大語言模型綜合評測報告與肝癌血漿microRNA標志物檢測系統前沿解析
在人工智能與精準醫療飛速發展的今天,兩個看似獨立的領域——大語言模型與生物醫學檢測——正以各自的突破性進展,共同推動著技術應用的邊界。本文旨在梳理并整合關于《2023年大語言模型綜合評測報告》的核心發現,并探討其在“肝癌血漿microRNA標志物檢測報告系統”等前沿醫療場景中的潛在應用價值。
一、 2023年大語言模型綜合評測報告核心洞察
近期發布的《2023年大語言模型綜合評測報告》及其相關數據表,為業界提供了全面、客觀的模型能力評估框架。報告通常涵蓋以下幾個關鍵維度:
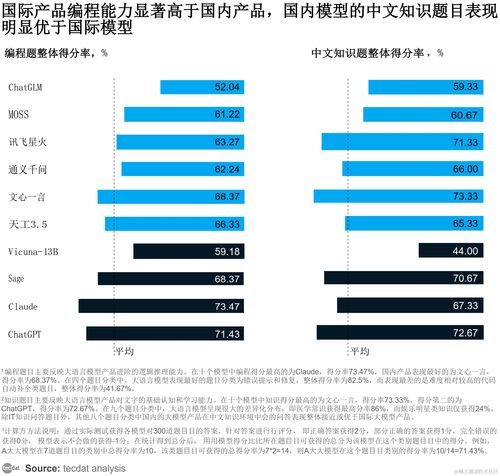
- 基礎能力評測:包括文本生成質量、邏輯推理能力、代碼編寫、多輪對話的連貫性以及多語言處理性能。報告通過標準化的基準測試(如MMLU、GSM8K等)量化比較了主流模型的表現。
- 專業知識與應用:深入評估模型在特定垂直領域(如法律、金融、醫療)的知識掌握與問題解決能力。在醫療領域,評測重點考察模型對醫學術語的理解、診斷推理的邏輯性以及醫學文獻摘要的準確性。
- 安全性與對齊性:評估模型輸出內容的安全性、偏見控制以及是否與人類價值觀對齊,這對于醫療等高風險應用至關重要。
- 效率與成本:分析模型的推理速度、部署資源消耗及API調用成本,這是商業化應用必須考量的實際因素。
該報告及附帶的原始數據表,為研究人員、開發者與企業提供了寶貴的選型依據和優化方向,揭示了模型從“泛化”走向“深化”和“專業化”的發展趨勢。
二、 肝癌血漿microRNA標志物檢測報告系統的技術內涵
肝癌的早期診斷是提高患者生存率的關鍵。血漿microRNA(miRNA)作為一種穩定的循環生物標志物,在肝癌的早期篩查、輔助診斷、預后評估及療效監測中展現出巨大潛力。一個現代化的“肝癌血漿microRNA標志物檢測報告系統”應具備以下核心功能:
- 高通量數據分析:系統能自動處理高通量測序或定量PCR產生的原始數據,進行miRNA表達譜的定量、歸一化和質量控制。
- 智能標志物識別與解讀:基于已知的肝癌相關miRNA數據庫(如miRBase、HMDD)和機器學習算法,系統能夠從海量數據中篩選出具有診斷或預后價值的特征性miRNA組合,并生成易于理解的生物學解讀(如調控的靶基因通路、與肝癌發生發展的關聯)。
- 自動化報告生成:系統整合分析結果、臨床參考范圍、患者信息,自動生成結構清晰、內容專業的檢測報告,為臨床醫生提供直接的決策支持。
三、 融合前沿:大語言模型在醫療檢測報告系統中的潛在應用
《2023年大語言模型綜合評測報告》所揭示的強大文本生成、知識整合與邏輯推理能力,為優化“肝癌血漿microRNA檢測報告系統”等醫療信息化工具開辟了新路徑:
- 增強報告的可讀性與個性化:大語言模型可以根據結構化的miRNA分析數據(如表達量、顯著性P值、ROC曲線下面積AUC值),自動生成流暢、專業的報告敘述部分。它能夠用通俗語言向患者解釋“某個miRNA異常升高可能意味著什么”,同時為醫生提供深入的機制分析摘要,實現報告內容的個性化分層輸出。
- 輔助臨床決策解讀:結合最新的醫學文獻和指南,大語言模型可以作為智能助手,為檢測報告中出現的特定miRNA標志物模式提供基于證據的臨床意義解讀、鑒別診斷建議以及后續檢查或治療方向的參考文獻,但需嚴格限定在輔助角色,最終決策權在醫生。
- 數據洞察與科研助手:對于科研場景,大語言模型可以幫助研究人員從積累的檢測數據中規律、提出假設,甚至輔助撰寫部分研究分析內容,提升科研效率。
- 交互式查詢與教育:系統可集成對話功能,允許醫生或研究人員就報告中的任何細節進行自然語言提問,模型即時提供解釋,成為一個持續學習的知識庫。
四、 挑戰與展望
將大語言模型應用于醫療診斷系統面臨嚴峻挑戰:
- 準確性與可靠性:醫療容錯率極低,模型必須保證極高的事實準確性,避免“幻覺”。這需要專業的醫學知識微調、嚴格的輸出審核機制以及人機協同的工作流程。
- 數據隱私與安全:必須確保患者數據在傳輸、處理過程中的絕對安全與隱私合規。
- 監管與合規:作為醫療設備軟件(SaMD)的一部分,此類系統需要滿足嚴格的醫療器械監管審批要求。
大語言模型評測報告的持續進化,將推動更專業、更可靠的領域專用模型出現。而將這些能力與“肝癌血漿microRNA標志物檢測”等具體的、高價值的醫療場景深度融合,有望構建出下一代智能、交互、可信的輔助診斷與報告系統,最終造福于患者,提升醫療服務的質量與效率。
(注:本文為技術應用方向解析,提及的評測報告與檢測系統均為示例。實際應用中,請務必依據官方發布的最新報告、臨床驗證數據和相關法規進行操作與決策。)
如若轉載,請注明出處:http://www.1jn.net/product/8.html
更新時間:2026-05-12 19:28:56